Play
Dynamically assemble and match players

Author: William Wu, PM-Justice Core OS
Earlier this year our team was tasked with ensuring the scalability of our infrastructure while reducing costs and maintaining the same service quality. This is the first part in a series of articles that covers how we achieved this goal.
In this first edition, we will discuss how we tested and improved the key scenarios across the core services to hit our initial Concurrent User (CCU) target of 500K.
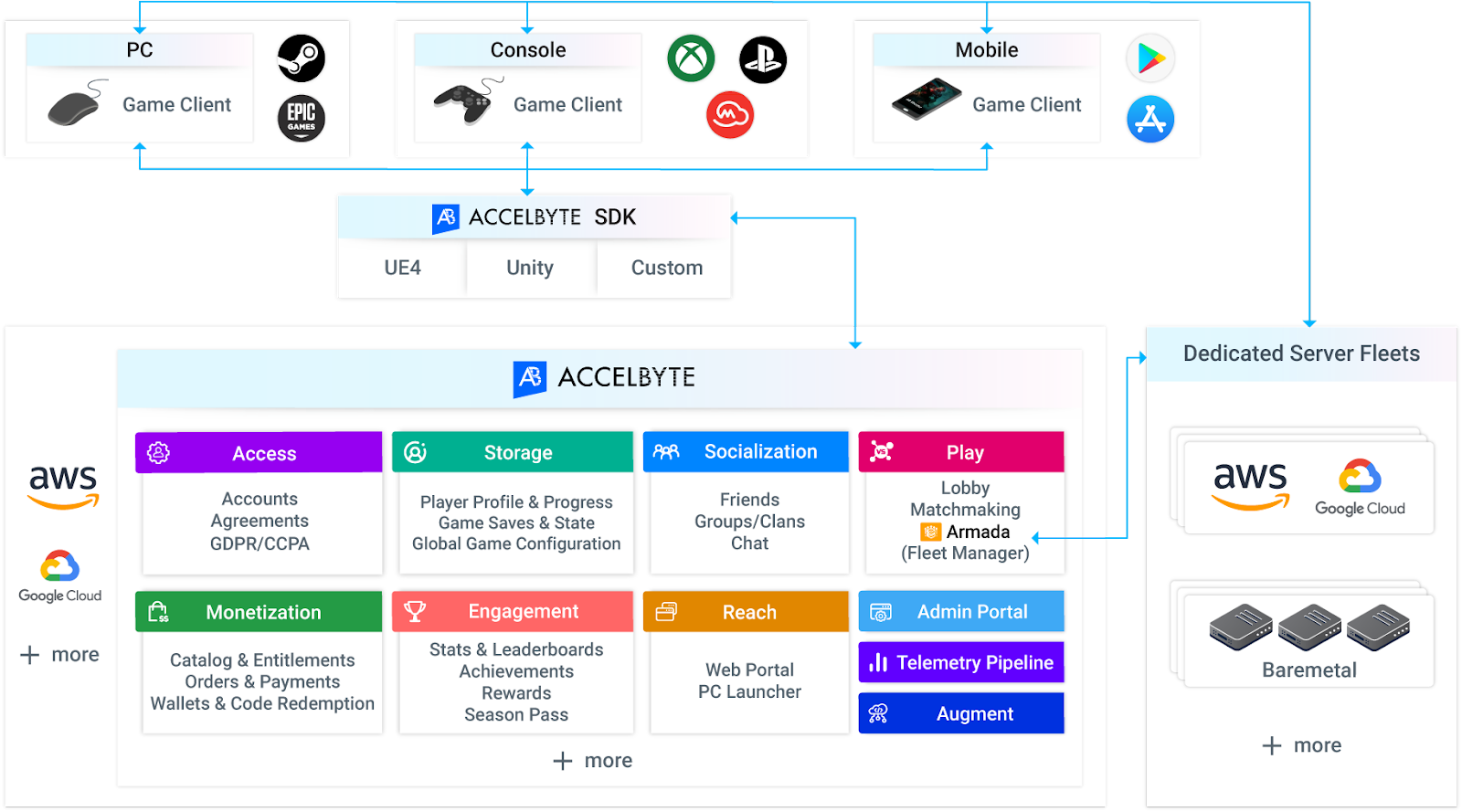
AccelByte Cloud is a suite of online services for games to scale to millions of players so the game developers can focus on the game, not the backend.
AccelByte Cloud does that through:
AccelByte Cloud is a collection of microservices, each organized by a business domain the service is responsible for. AccelByte Cloud adopted the microservice pattern from the start as it allows each service to be highly maintainable, testable, loose coupled, and independently deployable by a small team.
The first step is to set up a testing environment and tools. We deployed all our services in AWS EKS with a dedicated EKS cluster based on our production environment setup template.
The Attacker is a tool that we use to generate requests in our load test. Our Attacker was using Amazon EC2 Linux instances with Ubuntu OS. It allows us to scale up and scale down the size easily. We started the testing with the Attackers in the same AWS zone to tune the environment and tooling and moved the Attackers to a different region/zone as we scaled the testing to simulate more live-environment-like results.
To simulate a production environment, we create a set of seeding scripts to populate the environments with seeding data such as accounts, entitlements, friends, player records across the services. Depending on the scenario and service, we seeded some of the data directly to the database, and some via API calls.
We monitored some of our client's live environments, looked at the traffic pattern, and developed our attacker scripts to mimic those scenarios and traffic patterns. We used K6 as the tool to develop the scenario as it's scriptable in plain Javascript, has a great scripting API, and supports both RESTFul and Websocket calls.
There are four things we need to figure out:
Test targets:
Test methods:
Besides that, we adjusted different resource size, type, and count parameters based on the test results and monitored data to achieve the best cost-value purpose.
Monitoring is the key to getting visibility on the result and bottleneck of the system. We used a number of tools to monitor the system for different purposes.
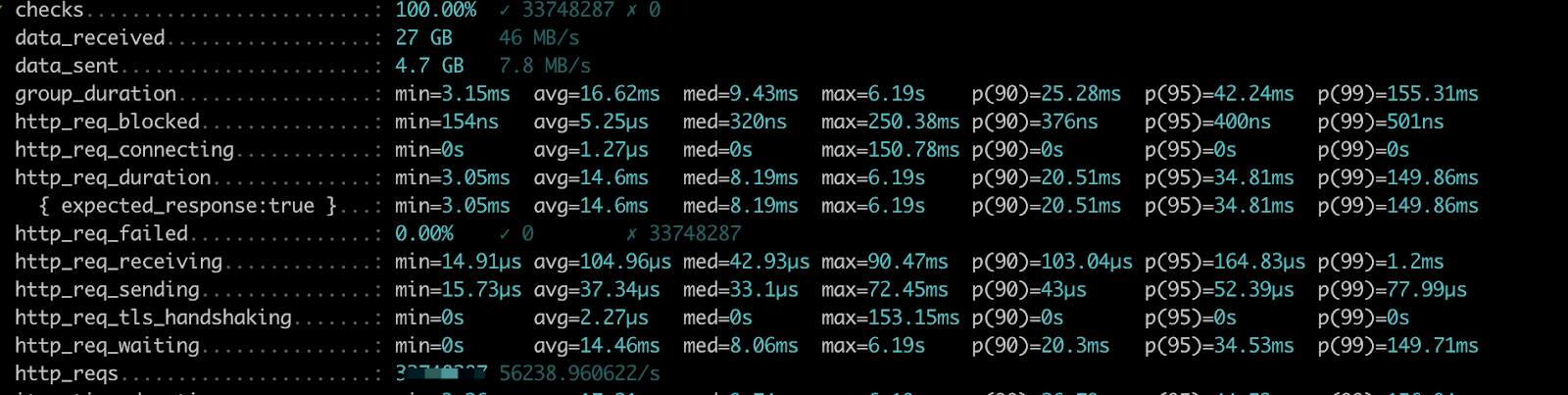
For most API, the response time can be done in 100ms, some complex API needs a longer time than that, but all queries can be done in two seconds.
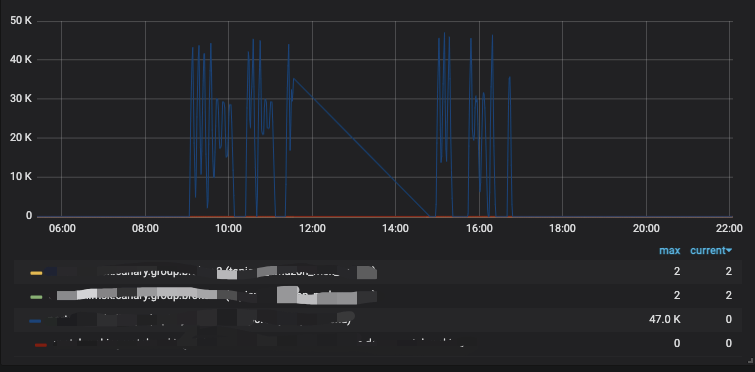
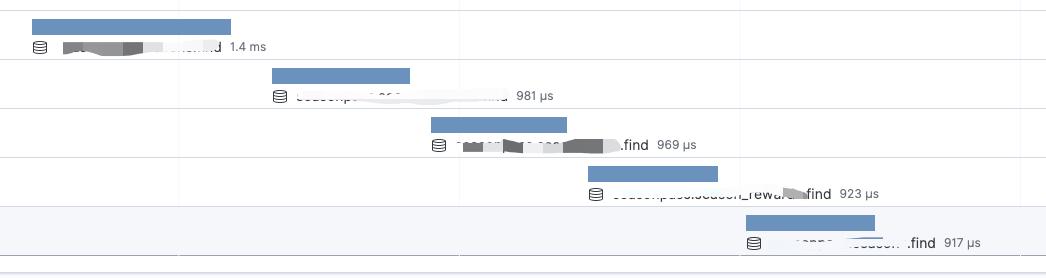
As we concluded the first phase of our load test effort, the system was able to comfortably handle 5 million transactions per minute, with 99% of our requests being less than 400 milliseconds, and a success rate greater than 99.95%. We also successfully reduced the cost of infrastructure by a large factor for each level of CCU target, and standardized our infrastructure setup for different load targets at 5K, 50K, 100K, 200K and 500K CCU.
We are currently working on integrating load testing as part of our development workflow, expanding the test scenarios, achieving higher targets of 1 million, 2-million, and 5-million CCU, and further reducing the infrastructure cost.
In the next article, we will go in-depth to discuss how we tested and scaled our lobby, matchmaking, and dedicated server manager services, and go over how to spin up 5-10K dedicated servers a minute.
To learn more about AccelByte's solutions request a demo here.
Reach out to the AccelByte team to learn more.

